『 代码随想录 』KMP算法

KMP算法
KMP算法本质上是用来找一个字符串中, 其子串所出现的频率;
**假设一个字符串为 **ABACBAACBACA 需要找子串 BACB所出现的次数;
其中此处我们能看到的最终结果:
**子串出现的次数为: **
1
这就是KMP算法所解决的问题;
1 BF解法
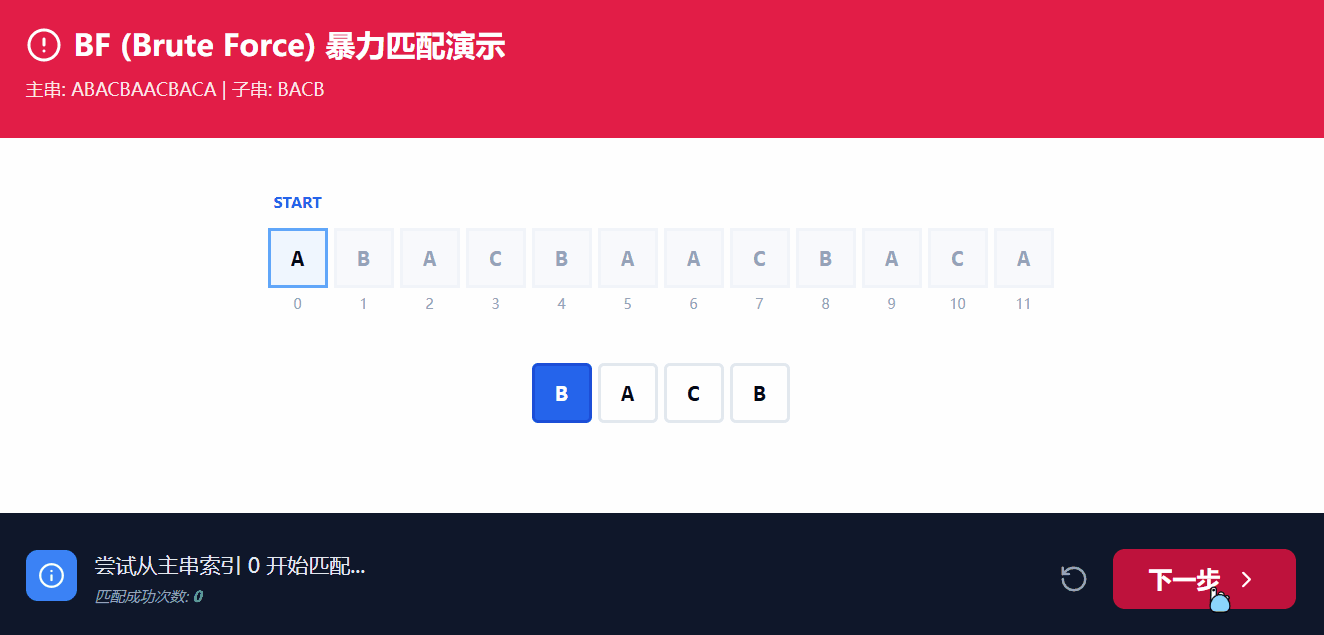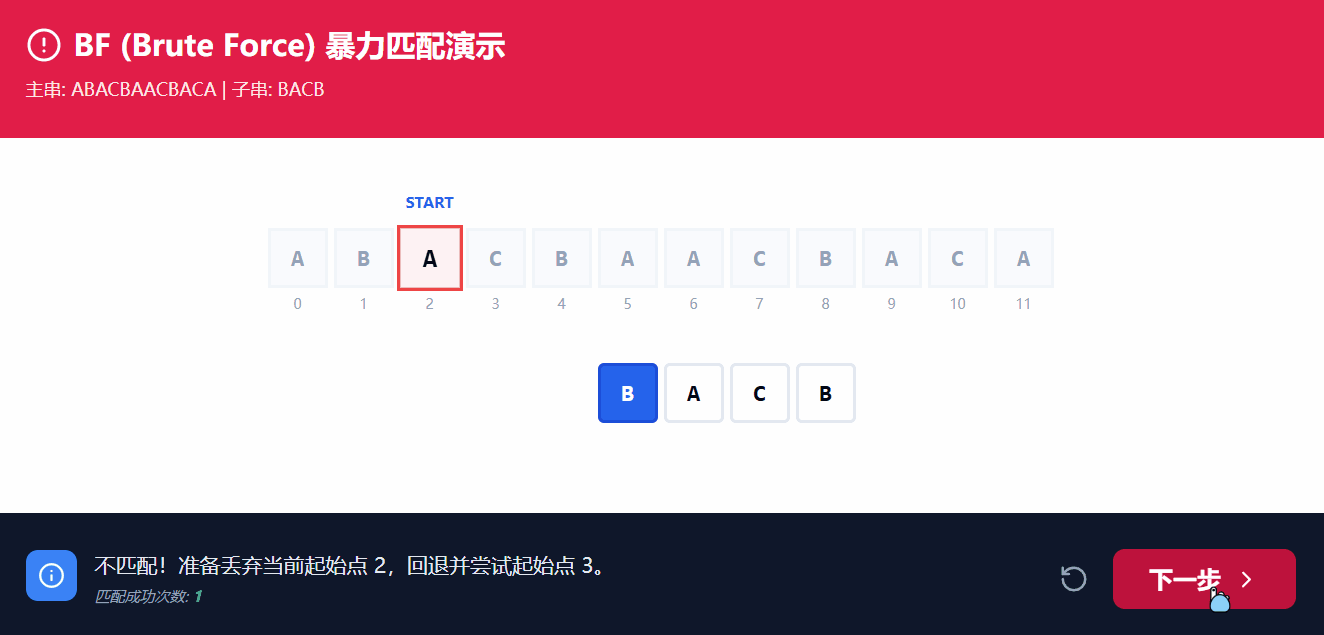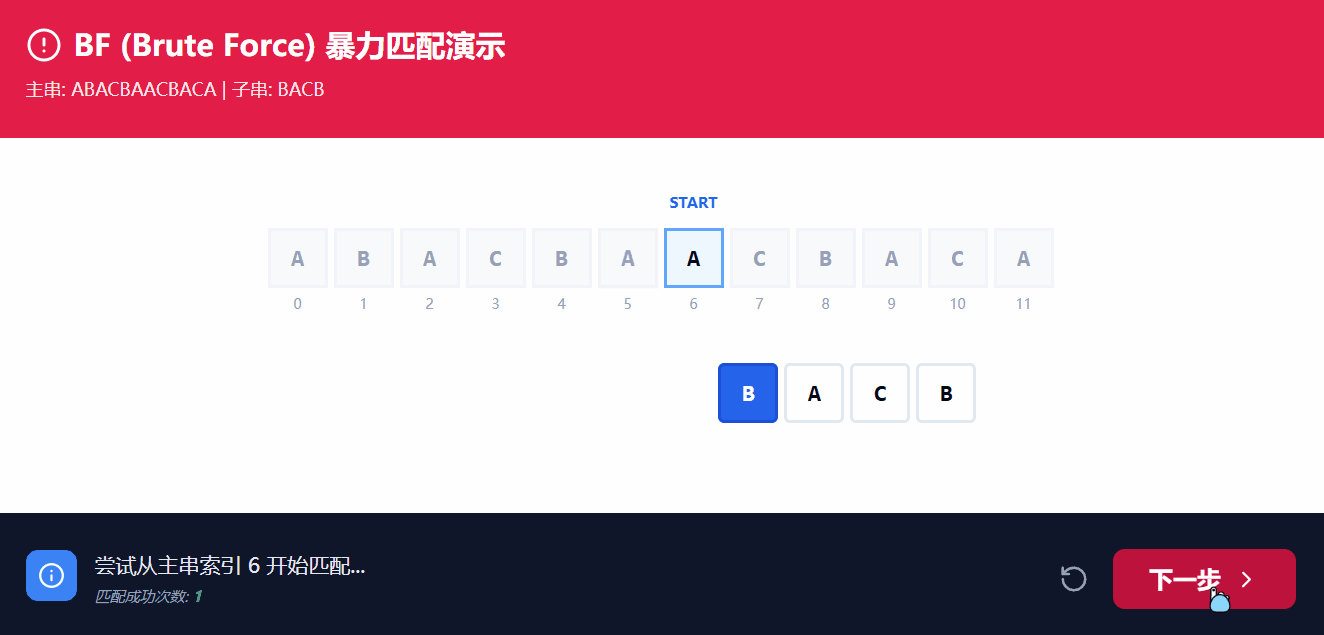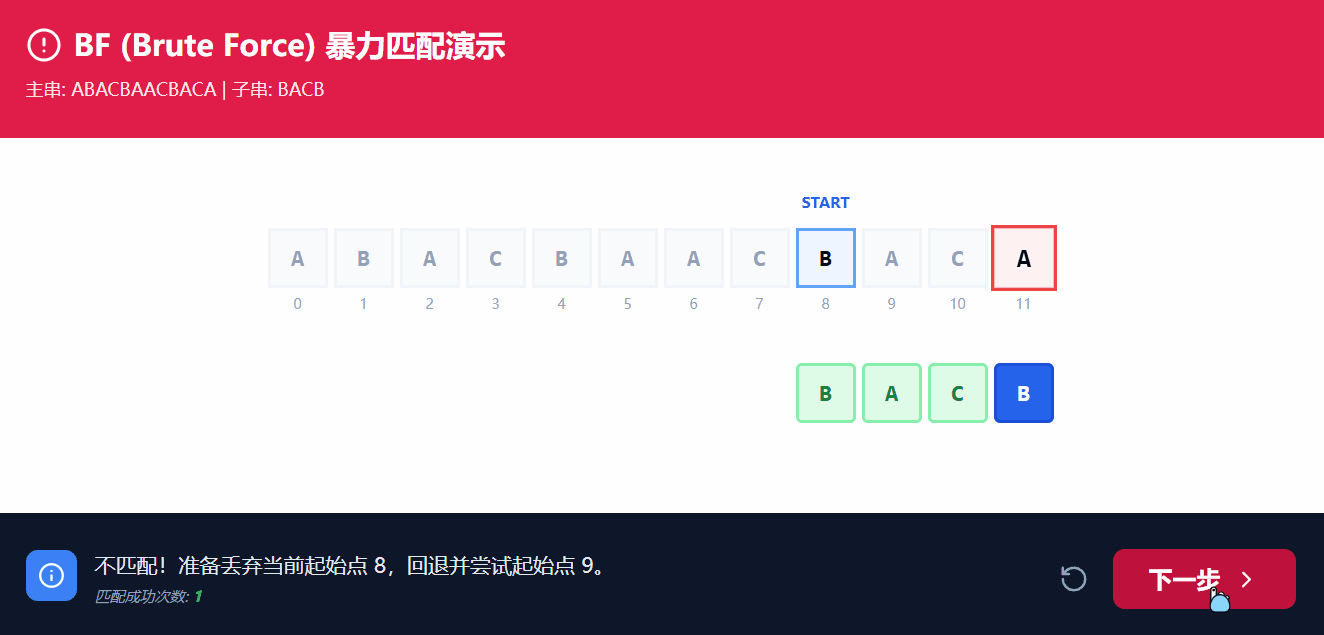
通常情况下, 我们可能会使用BF解法, 即=穷举暴力枚举=, 对应的时间复杂度为 O(M*N);
BF解法的核心思路就是, 以双指针对两个数组同时进行遍历, i遍历主串, j遍历子串, 逐个枚举;
通常情况下为:
for(int i = 0;i<MstrLen;++i){
for(int j = i; j<substrLen;++j){
/* ... 进行枚举并计算 ... */
}
}
若CSDN无法查看, 可[点击此处]访问(来自Gemini的Canvas的分享链接);
从上图GIF的演示中可以看到, 主串的指针i与子串指针j同时向后遍历, 但是最终还是需要将i回溯至所比较初始的+1位置, 而j则是回溯至0的位置, 频繁的回溯使得造成极大的时间开销;
而KMP算法的核心, 是通过减少主串指针无意义的回溯, 不回溯主串指针i, 而是通过特定的方式, 让子串记住此次匹配失败时, 所走过的哪些位置与主串对应的位置相等从而减少主串指针无意义的回溯;
2 KMP解法
KMP算法通过引入一个next数组, 使得双指针i和j在同时遍历且失败过后, 子串可以通过这个next数组来确认可以从子串开头向后偏移的有效步数, 从而减少两个指针的同时回溯, 将时间复杂度由O(N*M)提高至了O(N+M);
同例:
**假设一个字符串为 **
ABACBAACBACA需要找子串BACB所出现的次数;
此处的next数组为[0, 0, 0, 1];
实际的在调用过程中, 对应的步骤为如下:

- 首次比对
首先, 主串即为主串, 在KMP算法中, 子串被称为模式串, 对应的next数组即为上文所提到的,KMP算法基于BF算法所引入的next数组;

- 第二次比对
在首次的对比中, 主串与模式串的第一位不相同, 因此自然将模态串向后移一位, 表示从主串的第二位开始进行比较;

第二次对比中, 成功的找到了完整的子串, 此时COUNT为1;
我们将最后比对的指针位置, 主串的指针视为i, 模式串的指针视为j;

在此次比对之后, 为了防止可能会遗漏的子串, 因此需要将模式串对应的指针回溯至next[j-1]的位置, 那么下一次比对时的起始位置为:

- 第三次比对
第三次的比对, 在指针j在模式串下标为2时失效;

因此去查询next数组next[j-1]位置的位置, 这个位置存储的值为0, 说明模式串可从初始位置向后偏移0位, 实际上这里可以通过下标索引, 因此下一次比对时j指针依旧要回归最初始位置;
下一次比对时的起始位置如下:

- 第四次比对

第四次比对时, 同样在模式串开头的位置失效, 因此下次比对时i正常向后偏移一位; - 第五次比对

同样向后偏移一位; - 第六次比对

在第六次比对时, 同样的在模式串下标为3时比对失败, 因此去索引next数组中j-1位置时的偏移量, 结果为0, 说明下次比对中, 起始位置需要回溯回0;

**在下一次比对, 也是在第七次比对中, **i遍历走完, 最终结果为1;
在这个例子中, 我们似乎没有很好的完全看到next数组的作用, 但是可以通过对应记录的偏移量看到, i始终都是向后偏移, 我们只需要通过next数组来回溯模态串指针j所比对的位置;
我们可以再使用一个GIF, 通过另一个例子来演示next数组的完全的作用;
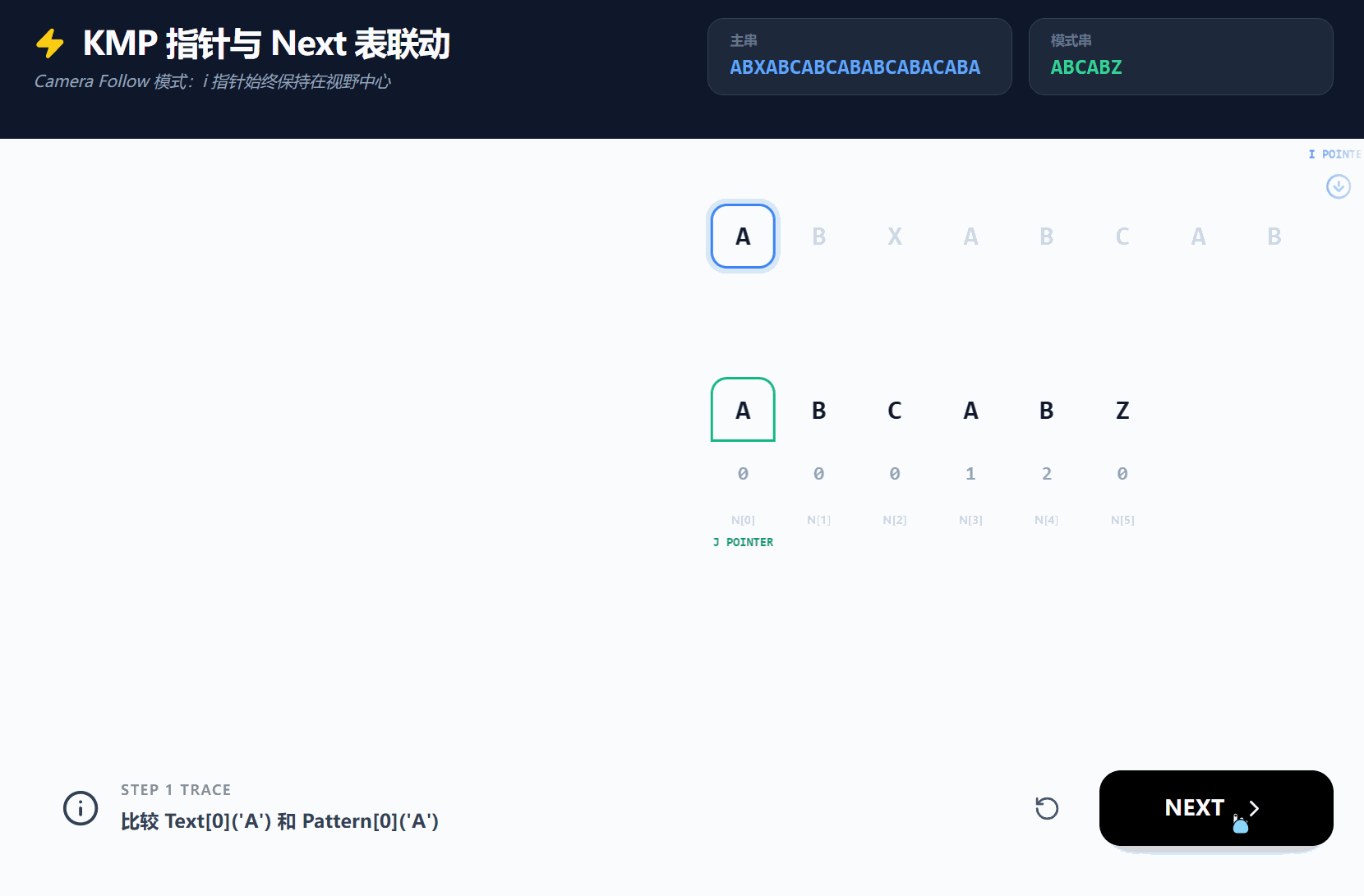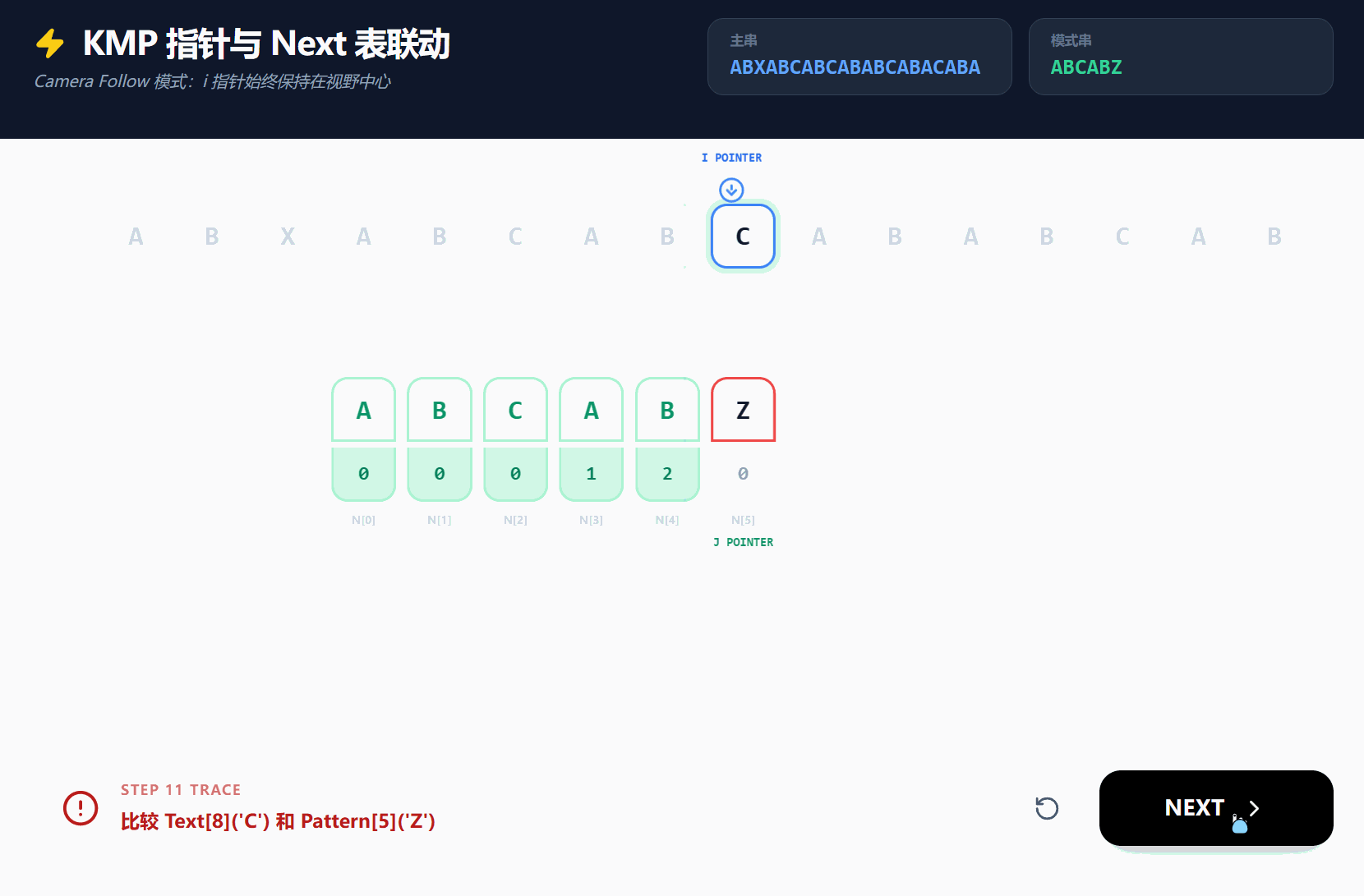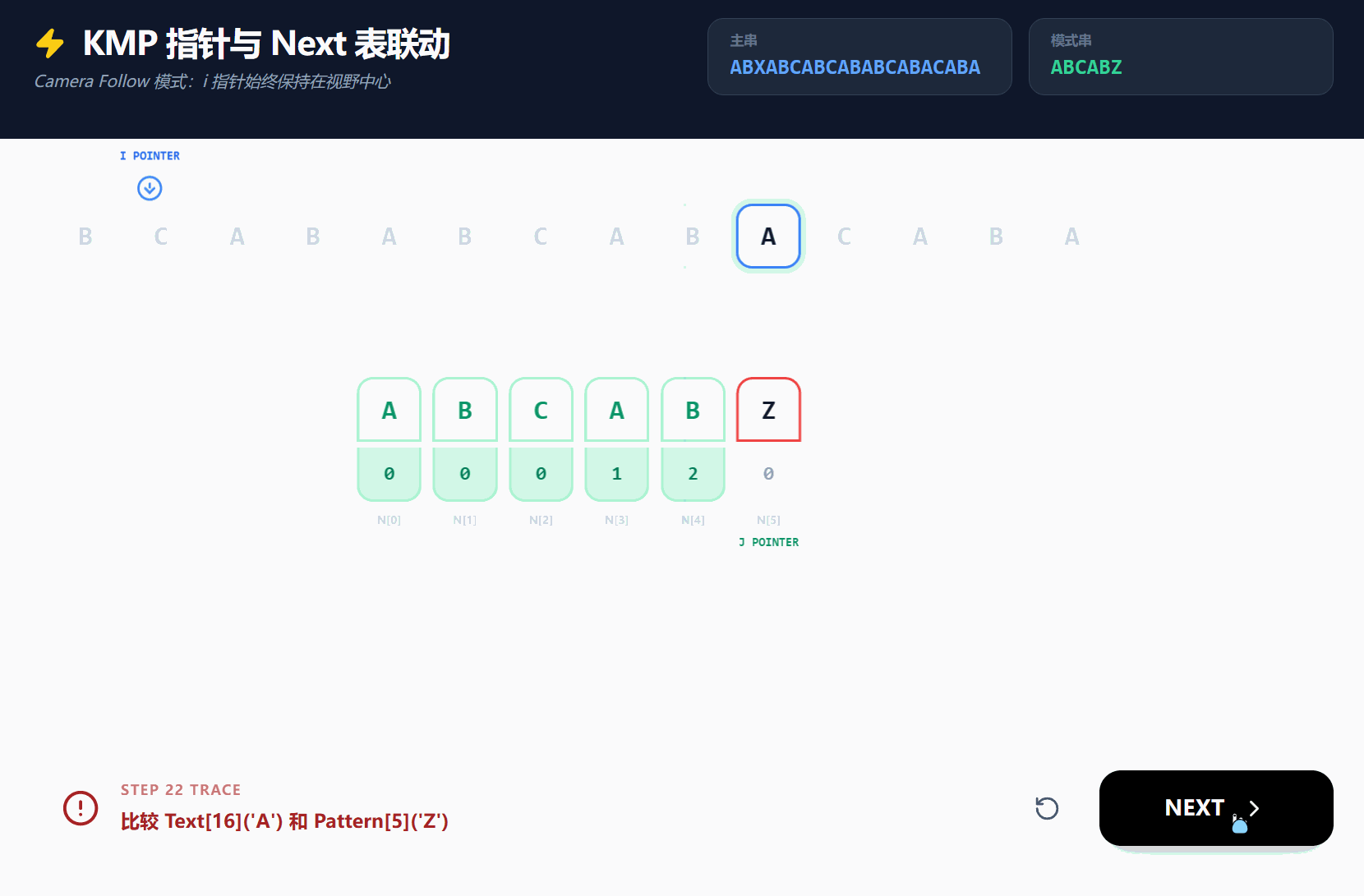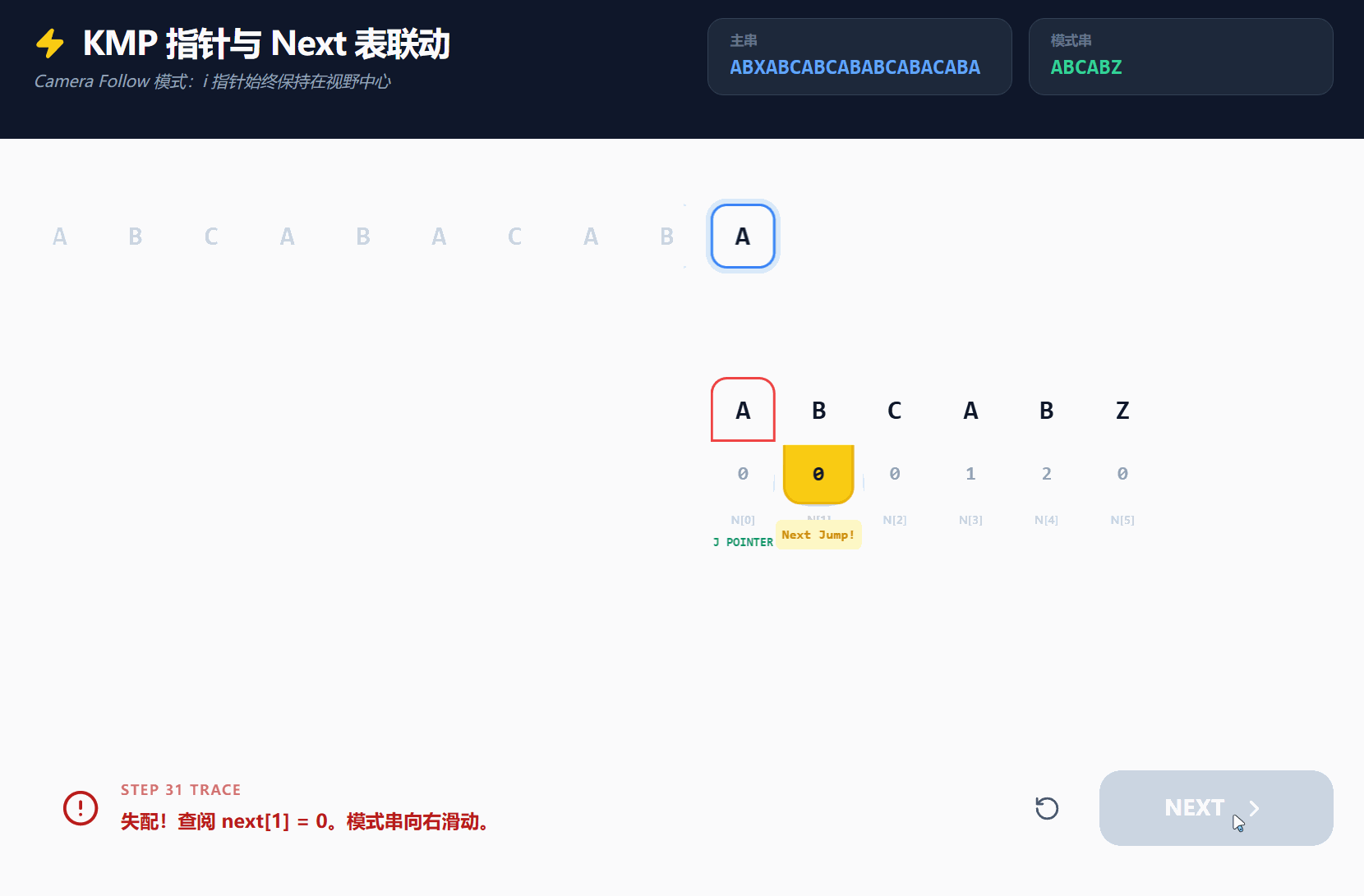
若CSDN无法查看, 可[点击此处]访问(来自Gemini的Canvas的分享链接);
因此假设存在Next数组, 那么KMP的调用代码为如下:
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
vector<int> getNext(char *substr){
/* 获取Next数组 */
}
int KMP(char *str, char* substr){
int strl = strlen(str);
int subl = strlen(substr);
if(strl < subl || subl == 0) return 0; // 1)智能剪枝 - 当子串长度大于主串, 或是子串为空时, 直接返回
vector<int> next = getNext(substr); // 2)获取next表
int count = 0; // 用于接受答案
int j = 0; // 用于遍历模式串
for(int i = 0;i<strl;++i /*用于遍历主串*/){ // 3) 开始比对
// 主串的遍历只依靠for循环
while(j>0 && str[i]!=substr[j]) j = next[j-1]; // 4) 当对比失效时 - 用于索引模式串下表j可回溯的位置
if(str[i] == substr[j]) ++j; // 5) 表示单个字符的比对成功
if(j == subl){
++count; // 6) 说明此次比对成功 - 次数+1
j = next[j-1]; // 7) 比对成功之后 为了确保不遗漏其他子串, 需要回溯模式串
}
}
return count; // 8) 主串遍历完毕, 说明全部比对完毕 - 返回出现次数
}
2.1 Next数组
Next数组(Next表), 本质上是从字串进行推演的;
- 从上面的例子中可能会带来疑惑, 为什么通过
Next表就可以进行偏移量的查看, 为什么只靠Next表就能做到?
Next表实际上是一张用于记录子串的每个子串的=最大公共前后缀长度=, 这里我们将=“子串”称之为“字符串”=, 在此处会更好理解一点;
- 最大前缀
最大前缀指的是一个字符串的除了最后一个字符的子串;
以字符串"abcde"为例, 其最大前缀为"abcd";
**对应的真前缀分别为: **=“a”=, =“ab”=, =“abc”=, =“abcd”=; - 最大后缀
最大后缀指的是一个字符串除了首字符的子串;
以字符串"abcde"为例, 其最大后缀为"bcde";
**对应的真后缀分别为: **=“e”=, =“de”=, =“cde”=, =“bcde”=; - 公共前后缀
公共前后缀实际上就是真前缀和真后缀的交集, 上述所举的这个例子"abcde"并没有公共前后缀;
我们再举一个有公共前后缀的例子示例:
- 以字符串
"ABAB"为例:- 真前缀:
“A”, “AB”, “ABA” - 真后缀:
“B”, “AB”, “BAB” - 公共前后缀:
此处的公共前后缀只有一个, 即为“AB”, 且长度为2;
- 真前缀:
Next数组则为, 一个字符串, 从左往右遍历, 找他们的当前的最大公共前后缀长度;
- **接下来以字符串 **
"ABCABZ"为例:
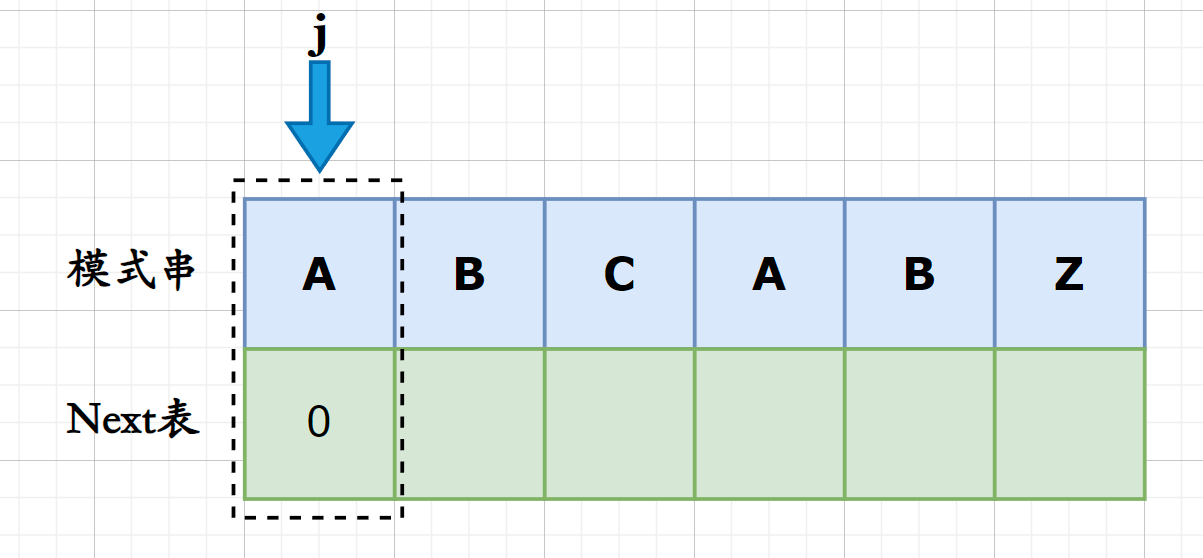
首先模式串的首位必然没有公共前后缀, 因为其不存在最大前缀和最大后缀, 因此为0;

当下标为1时, 子串为**“AB”, 对应的真前缀为**A, 真后缀为B, 不存在最大前后缀, 因此无最大公共前后缀;

当下标为2时, 相同, 真前缀为["A", "AB"],真后缀为["C", "BC"], 无交集, 无公共前后缀, 因此最大的公共前后缀为0;

当下标为3时, 子串的真前缀为["A", "AB", "ABC"], 真后缀为["A", "CA", "BCA"], 公共前后缀为"A", 最大公共前后缀长度为1;

下标为4时, 真前缀为["A", "AB", "ABC", "ABCA"], 真后缀为["B", "AB", "CAB", "BCAB"], 公共前后缀为["A", "AB"], 最大公共前后缀长度为2;

下标为5时, 真前缀为["A", "AB", "ABC", "ABCA", "ABCAB"], 真后缀为["Z", "BZ", "ABZ", "CABZ", "BCABZ"], 无公共前后缀为, 最大公共前后缀长度为0;
2.2 Next数组的推演代码实现
在2.1中, 我们以真前缀和真后缀的交集来判断对应的最大公共前后缀, 这表示我们可以通过枚举的方式;
但是枚举的方式在子串中获取Next一样很慢, 那么这样KMP将失去意义;
因此我们实际上通过Next自行推演, 记录一个单独的变量j来维护当前的最大公共前后缀长度, 并且逐渐向后遍历, 本质上和使用KMP解问题一样, Next数组推演的代码逻辑, 是通过子串来逆推出对应的最大公共前后缀;
逻辑是通过i的位置与我们所维护的当前的最大公共前后缀长度j的位置进行比较, 若是两个字符相同, 则增加j, 若是失配, 则去索引j-1的Next表的位置对应的子串位置, 是否相同, 不同则继续回溯, 直至相同或是所维护的最大公共前后缀长度回归于0, 则说明该子串不存在最大公共前后缀;
- **此处以 **
"ABACABA"为例:
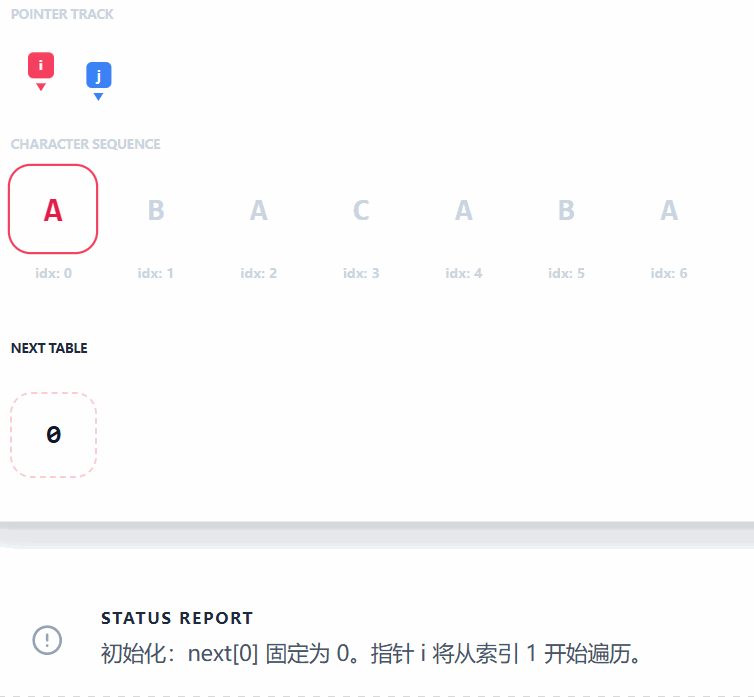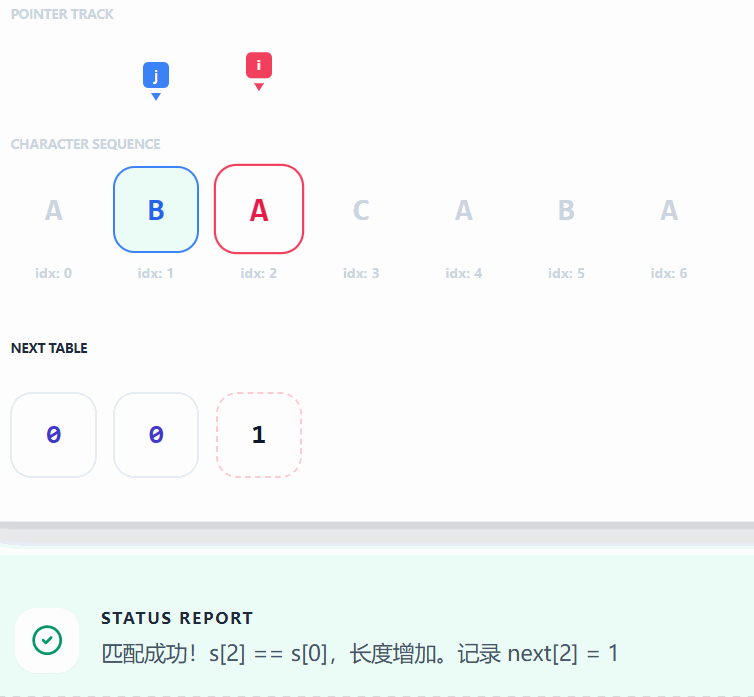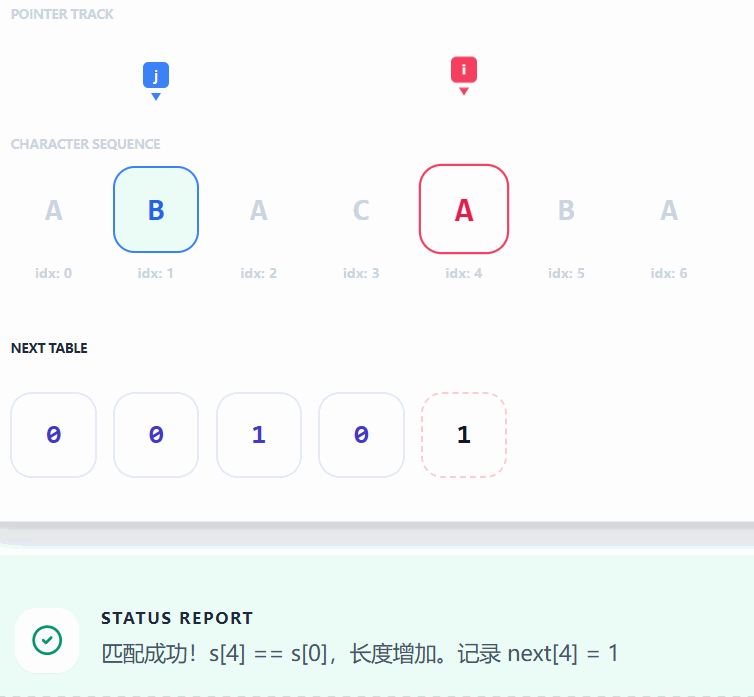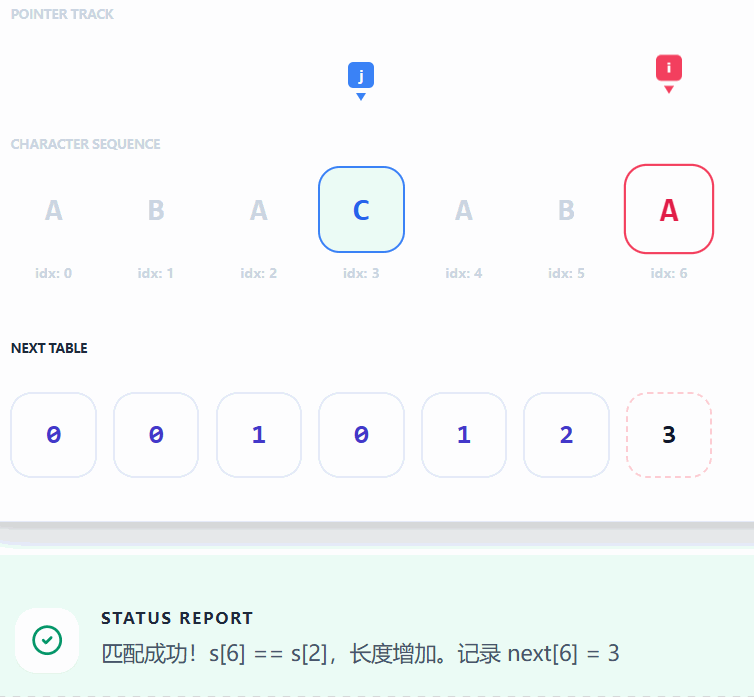
对应的代码实现为:
vector<int> getNext(char *substr){
int m = strlen(substr);
vector<int> next(m, 0); // 1) 初始化next数组
int j = 0; // 2) 初始化公共前后缀最大值
for(int i = 1;i<m;++i){ // 3) 遍历substr字符串
while(j>0 && substr[j]!=substr[i]) j = next[j-1]; // 4) 若是失配则去查询已有的next表
if(substr[j]==substr[i]) ++j; // 5) 想通说明公共前后缀最大值+1
next[i] = j; // 6) 赋值
}
return next;
}
3 完整代码
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
// 1. 制造备忘录:推演模式串自身的“最长真公共前后缀”
vector<int> getNext(char *substr) {
int len = strlen(substr);
// 初始公理:长度为 len,全部初始化为 0。
// 这天然确立了 next[0] = 0 的绝对特例(单字符无真前后缀)。
vector<int> next(len, 0);
int j = 0; // j 既代表当前已匹配的公共前后缀长度,也代表待比对的前缀指针
// i 是单向履带(后缀末尾),跳过特例 0,严格从 1 开始推演
for (int i = 1; i < len; ++i) {
// 【核心回退】:失配时,绝不使用 j--。
// 而是去查阅“已成功匹配部分 (j-1)”的备忘录,疯狂回退寻找次优解,直到退无可退 (j=0)。
while (j > 0 && substr[j] != substr[i])
j = next[j - 1];
// 【状态推进】:如果当前字符匹配成功,公共长度 j 顺理成章 +1
if (substr[i] == substr[j])
++j;
// 【一锤定音】:无论成功还是回退到底,将包含字符 i 在内的最终战果钉死在备忘录里
next[i] = j;
}
return next;
}
// 2. 实战查表:在主串 Mstr 中寻找模式串 substr 出现的次数
int NumOfstr(char *Mstr, char *substr) {
int count = 0;
int strl = strlen(Mstr);
int subl = strlen(substr);
// 提前生成模式串的防身备忘录
vector<int> next = getNext(substr);
// 智能剪枝:如果模式串为空,或者主串比模式串还短,直接判定为 0 次
if (subl == 0 || strl < subl)
return 0;
int j = 0; // 实战中的探路指针
// 主串指针 i 就像单向履带,全权交由 for 控制,绝对不回退
for (int i = 0; i < strl; ++i) {
// 【查表避险】:主串遇到失配,探路指针 j 查阅已匹配部分 (j-1) 的备忘录,瞬间空降到安全位置
while (j > 0 && Mstr[i] != substr[j])
j = next[j - 1];
// 字符匹配,探路指针 j 和主串履带 i 共同前进 (i 的前进在 for 循环头上)
if (Mstr[i] == substr[j])
++j;
// 【完美捕获】:探路指针走完了整个模式串的长度
if (j == subl) {
++count; // 记录一次成功匹配
// 【防漏判机制】:捕获成功后不能归零,必须强制查表回退,为可能存在的“重叠子串”留出退路
j = next[j - 1];
}
}
return count;
}
void test_func() {
char Mstr[] = "helloiamhello123";
char substr[] = "hello";
// 预期输出:2
cout << NumOfstr(Mstr, substr) << endl;
}
int main() {
test_func();
return 0;
}